HEP Software School: note about PL translation pipeline
На прошлом занятии я немного говорил о препроцессоре, в C/C++. Хотя сам по себе препроцессор специфичен лишь для некоторой части языков программирования вообще, важной темой для нас, как для людей нацеленных на разработку прикладного программного обеспечения является цепочка преобразований кода в языках программирования в целом. Думаю, пришла пора сделать беглую вылазку в мир формальных языков и искусственных грамматик.
Эта заметка состоит из трёх частей — первая посвящена небольшому знакомству с миром искусственных грамматик (пожалуй, эффективно — только тому что они есть, и в них есть такие штуки как лексема, литерал и ключевое слово). Её можно не читать, или, лучше, просто пробежать глазами, вчитываясь только там где есть курсив. Вторая часть более практически-важна, и посвящена рассмотрению искуственных языков чуть более детально, чем я говорил на семинарах. Третья часть быстро и решительно знакомит читателя с препроцессором.
Искусственные грамматики
Довольно скоро после изобретения первых вычислительных машин (ВМ), выяснилось, что многие простейшие алгоритмы и концепции удобно выражать в неком понятийном виде, скрывающим элементарную деятельность регистров ВМ. В самом деле, если вы хотите, скажем, записать в два восьмибитовых регистра процессора целое число кодированное 16-ю битами, и затем осуществлять какие-то арифметические операции над ним, то удобнее выражать это действие в виде абстрагирующемся от деталей реализации, и не думать о двух каких-то регистрах, а думать о числе как о числе.
Низкоуровневый язык ассемблера, в принципе, позволял скрадывать детальность и сложность простейших операций за определёнными подпрограммами. Комбинируя их затем различным образом, естественно было прийти к наборам идиом, позволяющих говорить об определённой предметной области в терминах присущих ей самой, а вовсе не техническим средствам ВМ: для арифметики — в терминах чисел и арифметических операций, для строковых выражений — в терминах строк и слов. Даже сама работа с ВМ по мере их усложнения стала нуждаться в понятиях более высокой выразительности, чем простейшие конечные автоматы — страницы памяти, адреса устройств, файлы и директории на дисках, etc.
Даже языки ассемблера имеют вполне какую-то простейшую
искусственную грамматику в которую входят правила записи инструкций и
разметки кода: mov AX,BX состоит из имени инструкции (mov) и разделённых
запятыми имён регистров процессора (AX, BX), а объявление процедуры
непременно содержит, собственно, имя процедуры (procName PROC ...
procName ENDP).
Строго говоря, вы можете конструировать простейшие грамматики и сами, букально из подручных средств.
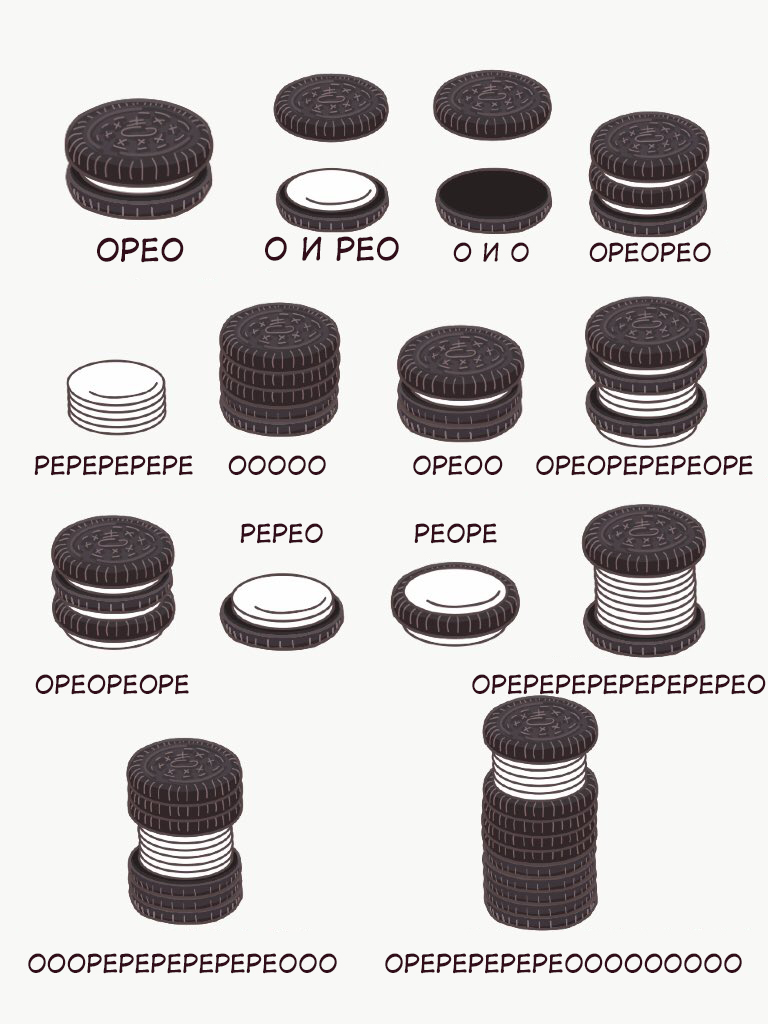
(пример простейшей грамматики из печенек OREO™)
К настоящему времени теория формальных языков [1, 2] и искусственных грамматик очень развита, имеет свой математический аппарат, и в целом — вполне себе фундаментальное научное знание. Однако нам нет нужды соприкасаться с ней вплотную, и хватит лишь весьма беглого инженерного знакомства. Интересующимся я мог бы рекомендовать, в качестве факультативного чтения, познакомиться с нотацией Бекаса-Наура (БНФ) — наиболее распространённом способе записи искусственных грамматик, которая может быть полезна вам на случай создания собственных DSL (domain specific languages), и часто встречается в академической литературе.
Действительно же нужен нам лишь узкий круг фундаментальных понятий из этой теории:
- токен (калька с англ. "token") или лексема — минимальная символьная последовательность идентифицирующае ту или иную смысловую единицу. При работе со строками (например, разборе входного файла с текстовыми данными) вам часто предстоит решать задачу токенизации — выделения элементов из текстовой последовательности. Например, считывание текстового файла в котором в несколько столбцов записаны числовые значения, будет непременно требовать разбиения строки на основе выбранного способа разметки (напр. по пробелам). Разница между токеном и лексемой состоит в контексте применения: "токен" обычно используется для простейших языков (конфигурационных файлов, файлов с данными), о "лексемах" же говорят в контексте более сложных языков, где есть управляющие последовательности, модификаторы поведения и многоуровневая грамматика, то есть там где возникает необходимость говорить о сложном лексическом разборе (англ. lexing). Будет правильно сказать, что всякий лексический разбор подразумевает токенизацию, но не всякая задача токенизации включена в лексический разбор, и это зависит от того, сколь сложна целевая грамматика (да, числа в три столбца — уже вполне себе грамматика).
- литерал —
записанное в коде программы значение. Высокоуровневые языки позволяют вам
указывать значения простейших типов — числа и строки. Везде где
встречаются выражения типа
int a = 42илиconst char myStr = "some thing",foo("bar"), полезно понимать что литерал будет помещён в объектный код приложения или библиотеки как статический блок данных. Вульгарным но эффективным пониманием литерала было бы сказать, что всякий токен в программе который есть значение — литерал. Литералы одного типа могут различаться по способу записи, строго из соображений удобства записи человеком в тот или иной момент. Так, в большинстве языков, вы можете записать число 16 целочисленным литералом либо как16(в десятичной форме), либо как020(в восьмиричной), или как0x10(в шестнадцатиричной). Все три записи будут интерпретированы как целочисленный литерал означающий число 16. Хотя для вас более актуальным будет пример литерала вещественного числа:123.657и1.23657e+2— литералы выражающие одно и то же число. - идентификатор — лексема ссылающаяся на объявленную (или объявляемую) сущность: переменную, функцию, пользовательский тип данных, etc.
- ключевое слово — управляющая лексема языка. Сюда входят
системные идентификаторы-имена типов, слова
for,if,switch,return, etc.
Фундаментальное правило почти любого искуственного языка: вы не можете использовать идентификаторы совпадающие по именам с ключевыми словами, или выглядящие как литералы. На однозначных различиях лексем построен, собственно, весь процесс лексического разбора.
Весь предыдущий текст в самом деле я написал только за тем, чтобы подвести к
этому (довольно простому в сущности) правилу. Так, например, компилятор языка
Си интерпретирует 42 как целочисленный литерал на этапе лексического разбора
и никак иначе потому что он начинается с цифры. По той же причине вы не сможете
объявить переменную или функцию с именем for — эта символьная
последовательность уже зарезервирована в лексике Си для ключевого слова.
Для примера взглянем на известную конструкцию объявления функции в Си:
1 | void foo(){}
|
Здесь void — ключевое слово, которое в контексте объявления функции будет
интерпретировано как "пустой возвращаемый тип", а foo — идентификатор.
Компиляция vs интерпретация
Будет правильно сказать, что для всякого практически-полезного искуственного языка существует интерпретатор — программа, производящая чтение человеко-читаемого кода в некое внутреннее представление (internal representation) компьютерной программы или структуру данных.
Так простейшая арифметическая операция 2 + a будет, скорее всего,
преобразована интерпретатором в структуру данных, содержащую некий
идентификатор бинарной операции (+), узел содержащий значение 2 и узел
ссылающийся на переменную a.
Относительно того что происходит с этим внутренним представлением затем,
языки разделяют на компилируемые и интерпретируемые имея в виду, что
последние обычно выполняются без генерации объектного программного кода для
процессора: в самом деле, после интерпретации 2 + a во внутреннее
представление, ничто не мешает выполнить (evaluate) это выражение, задавшись
каким-нибудь значением a. В случае же компилируемых языков, внутреннее
представление обычно преобразуется в машинный код.
Компилируемые языки, как правило, быстрее интерпретируемых, а объектный код меньше файлов с исходными кодами по объёму. Эти две причины по большей части обуславливают актуальность компилируемых языков в наши дни.
Примеры компилируемых языков: C/C++, Fortran. Примеры интерпретируемых: Perl, Python, Java, Ruby, JavaScript. В настоящее время, правда, такое разделение не очень чётко: люди пишут компиляторы, производящие объектный код из программ на языке ранее имевшем только интерпретатор, создают различные диалекты (см. например CPython) упрощающие эту задачу, но вводящие в стандартную лексику языка некоторые дополнительные конструкции, а то и пишут "компиляторы" одного языка в другой — особенно славен этим JavaScript (см. например CoffeeScript, TypeScript, тысячи их). Для C/C++ существуют интерпретаторы производящие выполнение кода без компиляции (CLING во всем известном ROOT) — вам открывается возможность выбирать инструмент исходя не только из задачи, но и своего владения конкретным языком.
Однако, что полезно держать в голове физику-прикладнику не очень искушённому в теории формальных грамматик, так это лишь общую последовательность выполнения компьютерной программы. Это нужно прежде всего затем, чтобы верно идентифицировать ошибку, потому что на поиск и исправление ошибок (отладку) у вас всегда будет уходить гораздо больше времени чем на написание кода, и разыскать место возникновения ошибки — это в самом деле уже половина работы. Чтобы более доходчиво проиллюстрировать эту последовательность я нарисовал схематичную картинку.

Легко видеть, что первые два этапа для обоих типов языков, в принципе, совпадают:
- программа сначала проходит этап лексического анализа, при котором,
на основе введённого текста, строится некоторое внутренне представление, которое
чаще всего выражается в виде специальной структуры данных под названием
абстрактное синтаксическое дерево
(англ. abstract syntax tree, AST, замечание выше про
2 + a— это вот оно, да). - В принципе, для простейших языков вроде арифметического калькулятора, AST уже может в каком-то виде быть использовано для вычислений, однако чаще всего, там где языки допускают определение пользовательских процедур, переменных и т.д., необходимо построение более сложного внутреннего представления. Это и составляет предмет семантического анализа (parsing) — перевод лексических единиц во внутреннее представление: представление процедур, пользовательских типов данных и переменных в виде блоков данных удобных для последующей работы: оптимизации и/или исполнения.
Про оптимизацию (на схеме не обозначена, поскольку производится не всегда и не везде): с точки зрения разработчиков языка тут происходит всё самое интересное, а с точки зрения пользователей — самое магическое: интерпретатор, при помощи различных сложных алгоритмов анализа, осуществляет оптимизацию кода. Простейший пример: арифметика в формуле $1/(x+1) + (x+1)$ — вы видите, что подвыражение $x+1$ вычисляется дважды, хотя это и не обязательно делать для одного значения $x$. Компилятор может изменить код так чтобы посчитать его один раз¹.
На схеме не обозначен этап препроцессирования C/C++ поскольку и он является не самым общим местом. Его следует понимать как незначительную добавку к языку, как способ не писать лишнего, или, в некоторых случая добавить лукавую поэтическую искорку.
Препроцессор в C/C++
Препроцессирование кода в Си будет осуществлено ещё до этапа лексического разбора, собственно, самого кода. Всё препроцессирование (или, для русского уха может быть более удобным будет термин предобработка, но я не уверен) занимается исключительно текстовыми преобразованиями сводящимися к подстановке текста и управляется директивами препроцессора, имеющими весьма незамысловатый синтаксис:
- Они начинаются со знака октоторпа (
#) - Почти все из них имеют дело с т.н. макроопределениями (макросы,
англ. macros) — небольшими конструкциями осуществляющими примитивное
преобразование и подстановку текста, начинающими свою жизнь с директивы
#define.
Простейший случай: всем знакомая директива #include, которая велит
препроцессору поместить вместо себя содержимое какого-то файла. Знакома она нам
в двух формах:
#include <something>
#include "another"
т.е. либо обрамлённая значками арифметического сравнения, либо обычными
"дюмовыми" кавычками. Обе формы взаимозаменяемы и эквивалентны², однако
существует конвенция, согласно которой двойные кавычки должны использоваться
для включения пользовательских файлов, а <> — для файлов из сторонних
пакетов.
Работа с макроопределениями напоминает работу с переменными. Вы можете
определить макрос через директиву #define, и в этом случае определение может
появиться в любом месте после:
1 2 3 | MY_MACRO;
#define MY_MACRO 123
MY_MACRO;
|
В первой строке подстановка 123 вместо MY_MACRO не будет выполнена и после
препроцессирования она останется неизменной. В третьей строке подстановка будет
осуществлена.
Вы всегда можете велеть компилятору напечатать отчёт о ходе препроцессирования
и его результаты через ключ -E. Так, например, результаты препроцессинга трёх
строк выше, записанных в файл one.c:
$ gcc -E ./one.c
# 1 "./one.c"
# 1 "<built-in>"
# 1 "<command-line>"
# 31 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 32 "<command-line>" 2
# 1 "./one.c"
MY_MACRO
123
(здесь октоторп предваряет строки с отчётом лексера, а строки без него — получившийся после препроцессирования код)
Вы можете "отменить" макроопределение через директиву #undef — после неё
никаких подстановок произведено, понятно, не будет.
Макроопределения могут содержать любой текст, но часто используются для
определения различных констант: число $\pi$, например, определяется в
заголовочном файле math.h стандартной библиотеки как макрос M_PI:
$ grep M_PI /usr/include/math.h
# define M_PI 3.14159265358979323846 /* pi */
# define M_PI_2 1.57079632679489661923 /* pi/2 */
# define M_PI_4 0.78539816339744830962 /* pi/4 */
...
Другое известное уже вам макроопределение — RAND_MAX из файла stdlib.h:
$ grep RAND_MAX /usr/include/stdlib.h
#define RAND_MAX 2147483647
Разумный вопрос: а почему бы не воспользоваться обычной константой? Не
записать, например, const double pi = 3.14159265358979323846? Ответ на него
потребует некоторого размышления и знания того как обычно написаны
многофайловые проекты на Си. Дело в том что после раскрытия макроопределения,
код получит обычный литерал числа с плавающей точкой, в то время как имя
константы будет ссылаться на некоторый объект в памяти, значение которого
не будет известно в коде его использующем, до этапа линковки. Это послужит
препятствием для алгоритмов оптимизации.
Другой важнейшей особенностью макроопределений является возможность задавать им динамическое поведение. Делается это образом похожим на определение функции — нужно просто дополнить имя макроса круглыми скобками, где можно перечислить аргументы:
1 2 | # define MY_MACRO( foo, bar ) foo + bar + 3
MY_MACRO( 1, some )
|
Результатом раскрытия макроса во второй строке будет, как несложно догадаться,
1 + some + 3. Простейший пример полезности такого определения функции —
вообразите, что у вас есть, к примеру, такой код:
1 2 3 4 | do_something( myVar1, *myVar2, *myVar3, 1 );
do_something( myVar1, *myVar2, *myVar3, 2 );
do_something( myVar1, *myVar2, *myVar3, 3 );
do_something( myVar1, *myVar2, *myVar3, 4 );
|
То есь, пачка вызовов функции с длинной сигнатурой, где меняется только один аргумент. Вы всегда можете поступить, например, вот так, чтобы во-первых дать возможность читающему код человеку (коллеге, или себе через пару недель) сосредоточиться только на том что меняется, или, на этапе прототипирования, когда сигнатуру функции вам придётся не раз менять:
1 2 3 4 5 6 | # define DSMTH(x) do_something( myVar1, *myVar2, *myVar3, x )
DSMTH(1)
DSMTH(2)
DSMTH(3)
DSMTH(4)
# undef DSMTH
|
Ну и, конечно же, чаще всего вам придётся видеть, как в зависимости от
того, определён какой-либо макрос или нет, включаются или выключаются
определённые блоки кода. Делается это внутри проверки условия
#if defined(MY_MACRO) ... # endif. Так, например, если вы хотите
предусмотреть специальный режим сборки вашего кода, который будет печатать
диагностическую информацию, в норме ненужную пользователю, но необходимую
время от времени для отладки, вы можете опираться, например, на некое
глобальное макроопределение DEBUG:
1 2 3 | # if defined(DEBUG)
printf("debug: x=%f", x);
# endif
|
Этот приём используется настолько часто, что для конструкции вида
#if defined(MY_MACRO) и #if ! defined(MY_MACRO) лексикой препроцессора
C/C++ даже предусмотрены специальные сокращения: #ifdef MY_MACRO и
#ifndef MY_MACRO соответственно. Эквивалентный фрагмент:
1 2 3 | # ifdef DEBUG
printf("debug: x=%f", x);
# endif
|
Вообще, #ifdef/#endif и #ifndef/#endif — вполне себе расхожие конструкции,
используемые в C/C++ едва ли не чаще чем пресловутый #include (который вы,
разумеется, тоже можете заворачивать в условия подобного вида):
#ifdef USE_STD_MATH
#include <math.h>
#else
#include "mymath.h"
#endif
И последнее в теме про препроцессор: все компиляторы предусматривают тот или
иной механизм задания макроопределений из командной строки. Для компиляторов
GCC/CLANG синтаксис такого аргумента выглядит как опция с ключом -D:
-D<macro-name>[=<macro-value>]. Например:
$ gcc -DDEBUG=1 one.c
скомпилирует one.c как если бы в самом начале этого файла было
написано #define DEBUG 1.
Использовать макроопределение DEBUG в качестве простого способа управлять
конфигурацией сборки программы даже сделалось конвенцией. Это со всех сторон
обычное макроопределение, однако ставшее настолько общим, что даже ряд
системных заголовочных файлов предполагают что вы можете декларировать его
чтобы задействовать дополнительные отладочные механизмы.
Примечания
¹) На самом деле нет. Нет такой арифметической оптимизации в C/C++. Это чисто иллюстративный пример, хорошо передающий идею, но из-за технических аспектов языки этого семейства такой оптимизации лишены. Мы будем говорить об этом позже, когда обсудим некоторые расхожие практики при написании числодробилок.
²) Так было до недавнего времени. Новый стандарт закрепляет упомянутую
конвенцию, заставляя компилятор искать <>-файлы сначала в системных
директориях, а "" — в пользовательских
(разница -isystem и -I). Детали.
Comments

© Copyright 2016, under the auspices of Q‐crypt foundation / под эгидой Q-crypt foundation
Materials are free free for distribution under the terms of CreativeCommons Attribution ShareAlike CC BY SA 4.0. / Материалы свободны к распространению в рамках CC BY SA 4.0